资源信息
30天走向分布式 ccshih
走向分布式作者:ccshih 由 整理:邓草原
一个系统走向分散式,一定有其不得不为的理由。Scalability 是最常见的理由之一。
我先简单的将 Scalabilty 的需求分成两种:
• Data Scalability: 单台机器的容量不足以 (经济的) 承载所有资料,所以需要分散。如:NoSQL
• Computing Scalability: 单台机器的运算能力不足以 (经济的) 及时完成运算,所以需要分散。如:科学运算。在之後几天,我会试着就这两种需求来解析其中会遇到的问题与常见解法。
资源目录
Day 1: Scalability
Day 2:分散式系统的面向
Day 3: Partition
Day 4:为什麼有有些时候不要把 query 酒到所有机器上平行处理?
Day 5:资料切割的 metadata 管理
Day 6: Replication
Day 7:无强一致性及无法决定执行顺序带来的问题
Day 8:最终一致性
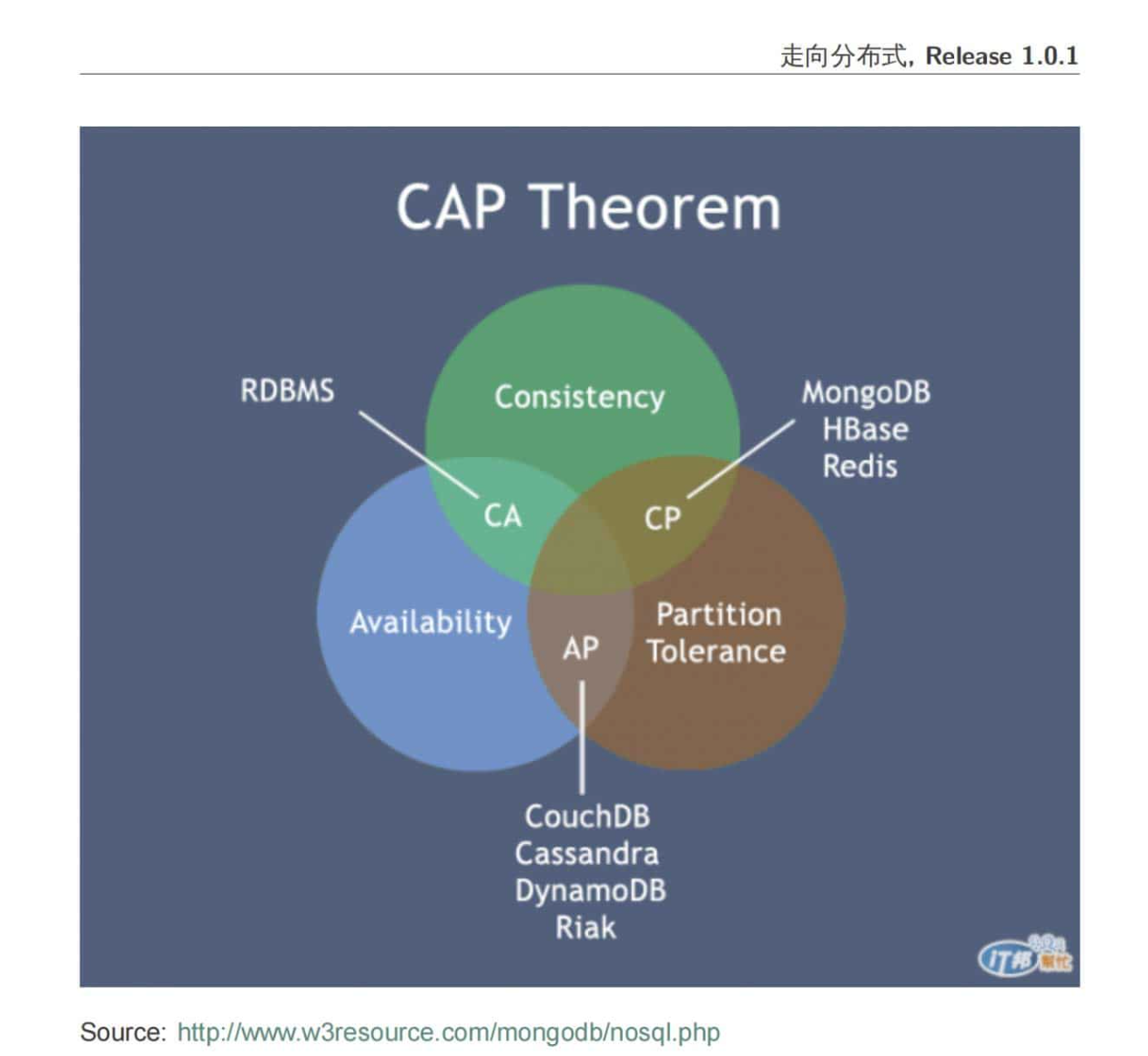
Day 9: CAP Theorem
Day 10: In-Memory data
Day 11: Zookeeper
Day 12: Zookeeper (续)
Day 13: Apache Kafka
Day 14: Apache Kafka (2)
Day 15: Apache Kafka (3)
Day 16: Apache Kafka (4)
Day 17: Apache kafka (5)
Day 18: Apache Kafka 与 Stream Computing
Day 19:分散式资料系统 v. 科层组织
Day 20: In-Memory 的技术议题?
Day 21:分散式运算系统
Day 22:分散式运算系统的沟通方式
Day 23: Stream Computing 的应用范围
Day 24: Stream Computing 特性
Day 25:选择 Stream Computing 框架
Day 26: Stream Computing 框架的组成角色
Day 27:如何追踪每一个 record 的处理进度
Day 28:错误处理机制
Day 29:从 Stream 到 Micro batch
Day 30: Stream States & Finale
资源下载
阿里云盘
