Loading...
忽然想到看小说在网站看很麻烦,而且老是弹广告,干脆写了个爬虫 可以直接搜索你要看的书,然后就可以全自动下载了 保存为当前目录的"小说"文件夹,里面会生成一个txt文档,小说会写进里面 自己想看的...
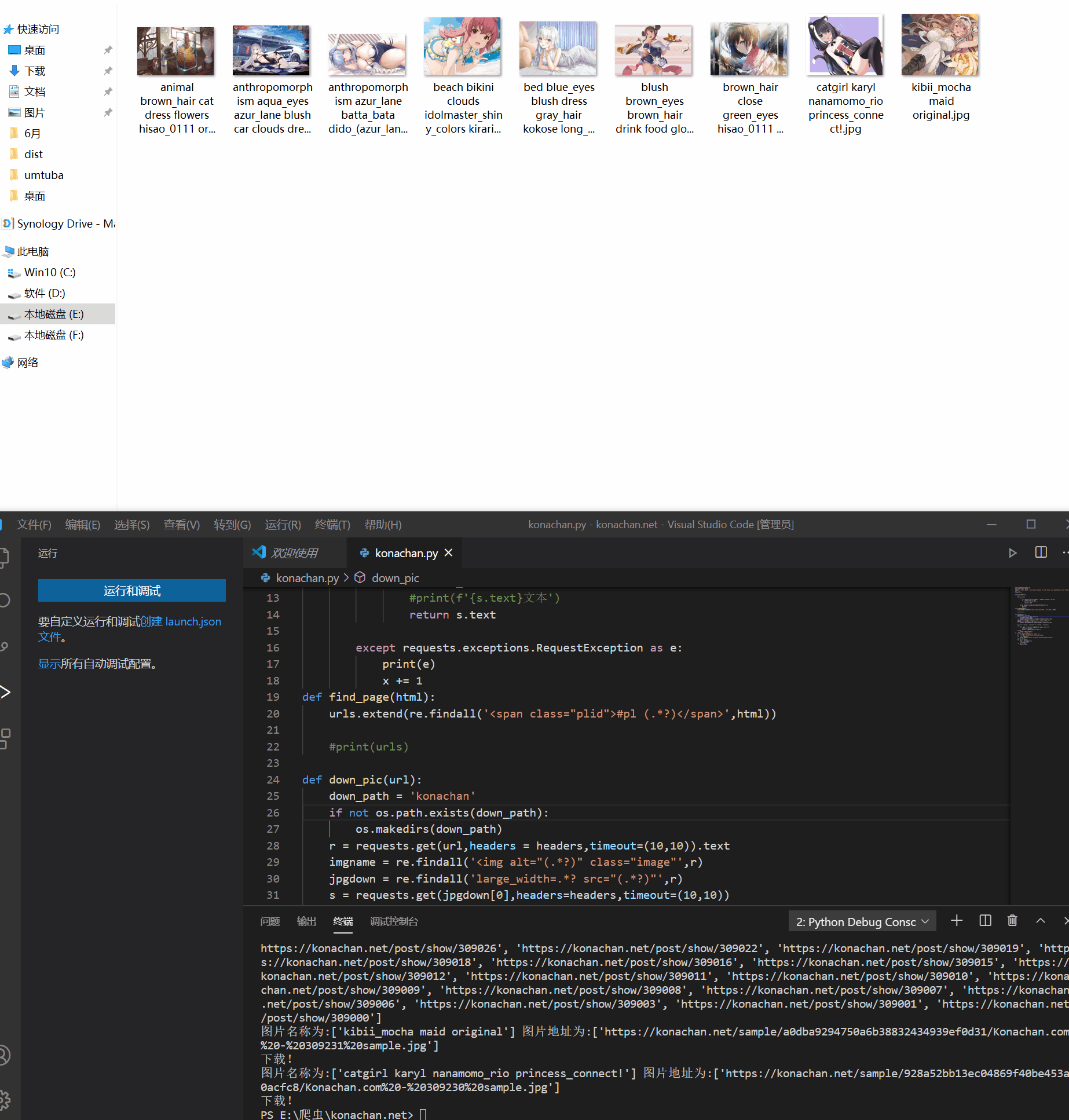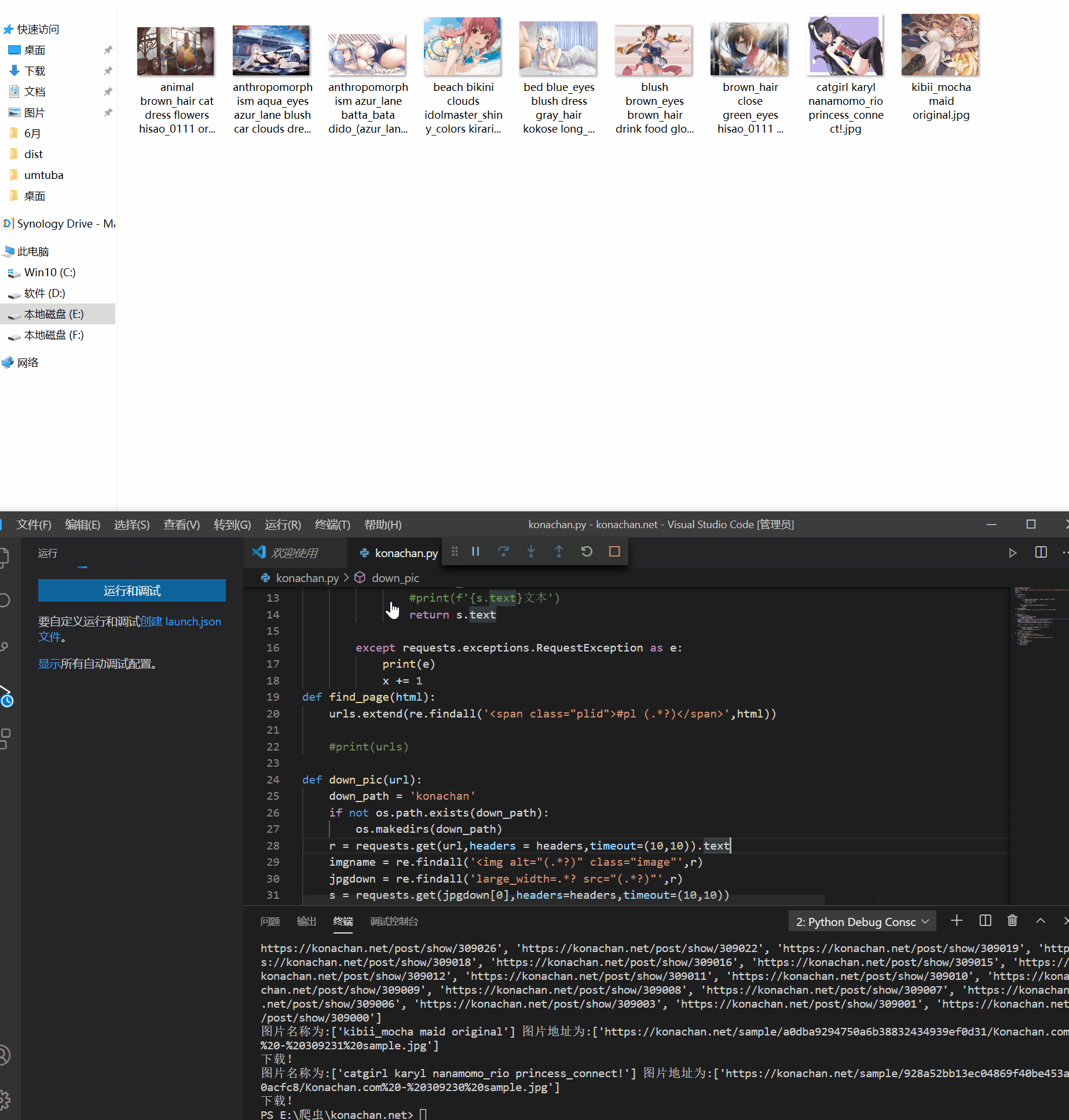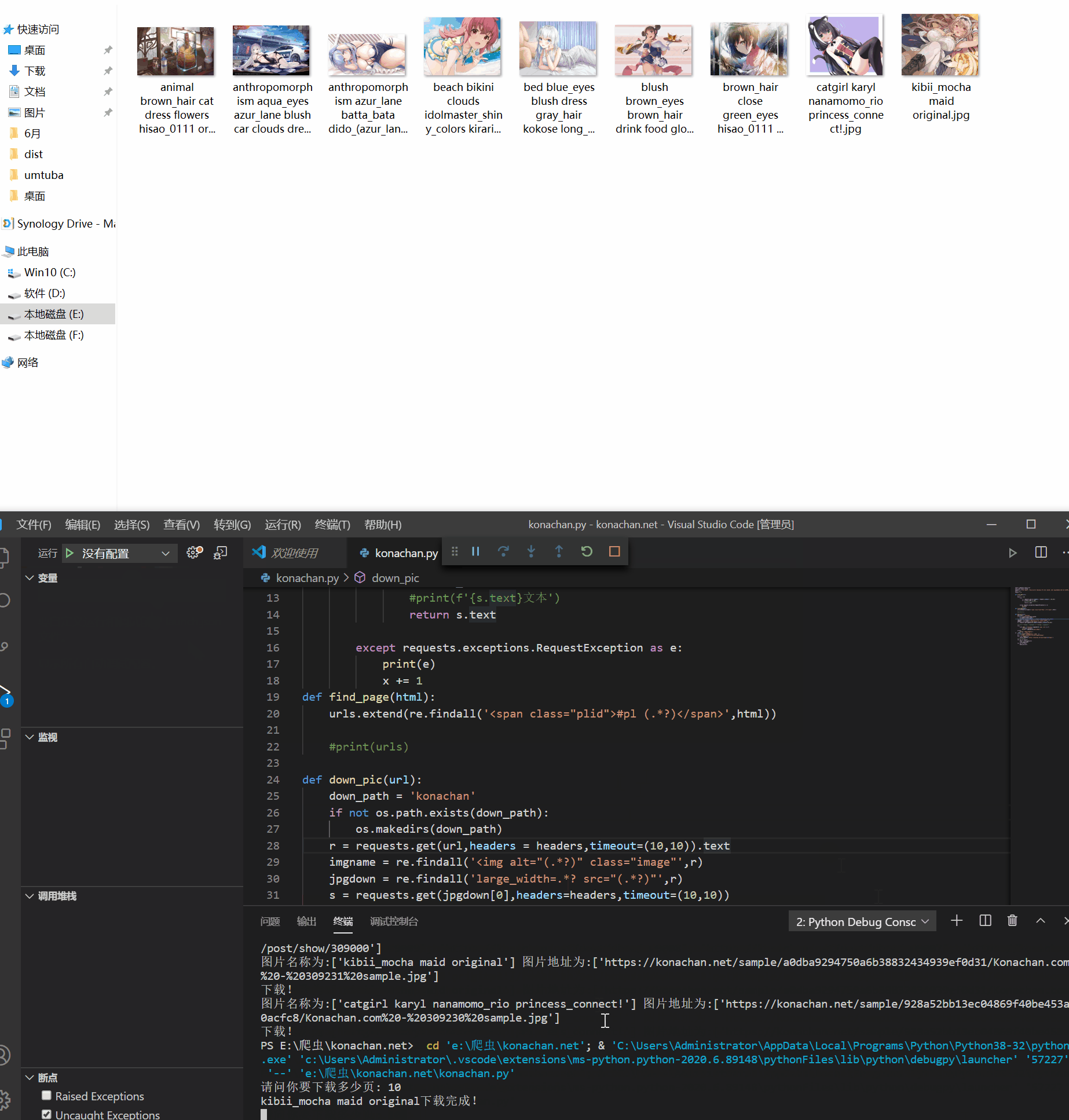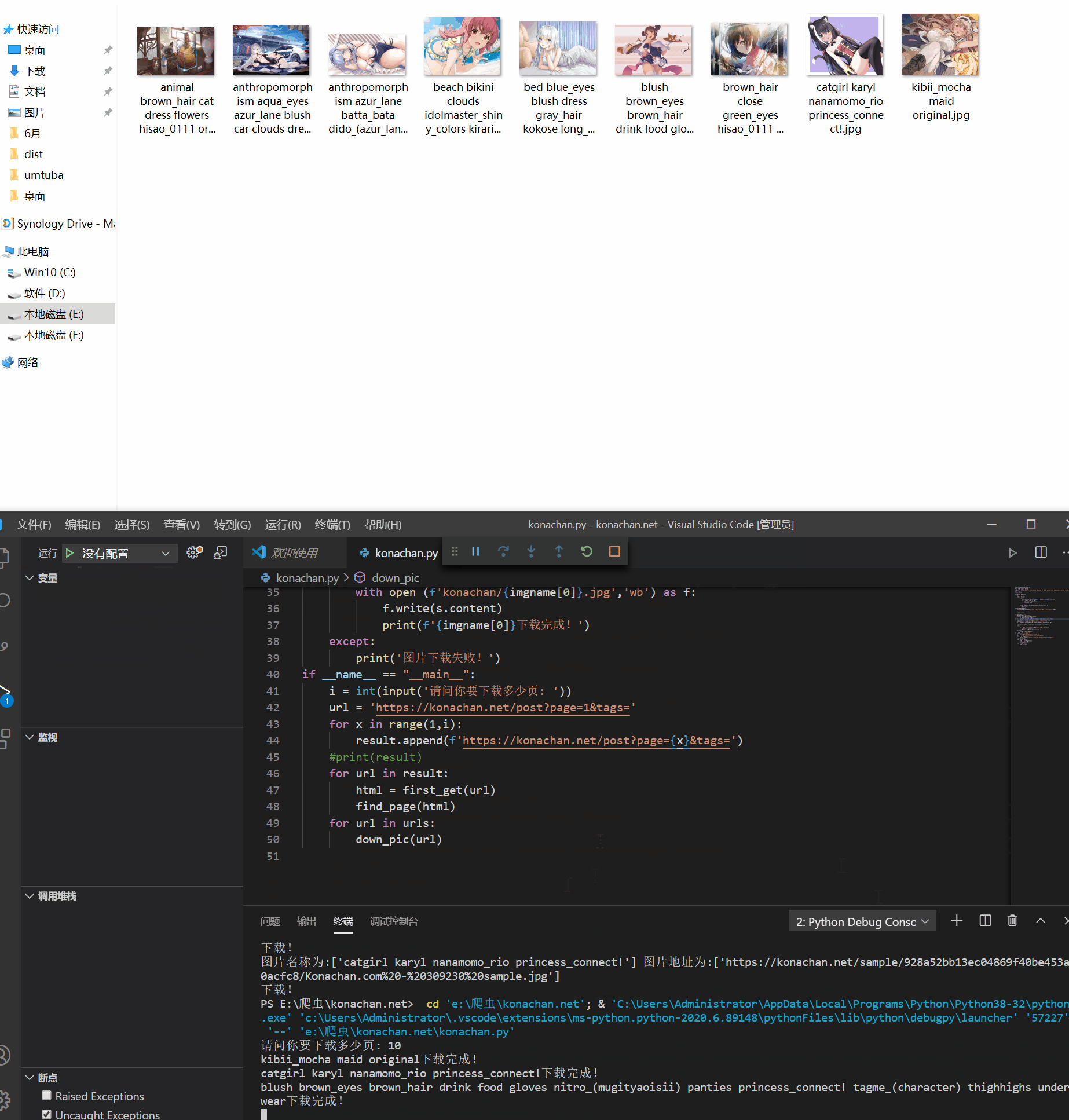
2020-07-26 13:25:36 星期日 问题已经解决,源码更新在最下面。 2020-07-26 10:04:35 星期日 发现bug,待修复 2020-07-26 10:00:54 星...
蓝奏云下载地址(仅限windows用户):https://www.lanzouw.com/iA9sNw7d9ta
之前写过一个优美图吧的整站图片爬取程序,由于使用的很多,或者说写这个站点爬虫的作者也很多,或者这个那个... 反正就是,站长觉得不对劲了,将他的站点加入了Ajax来加载更多的图片翻页,所以我之前...
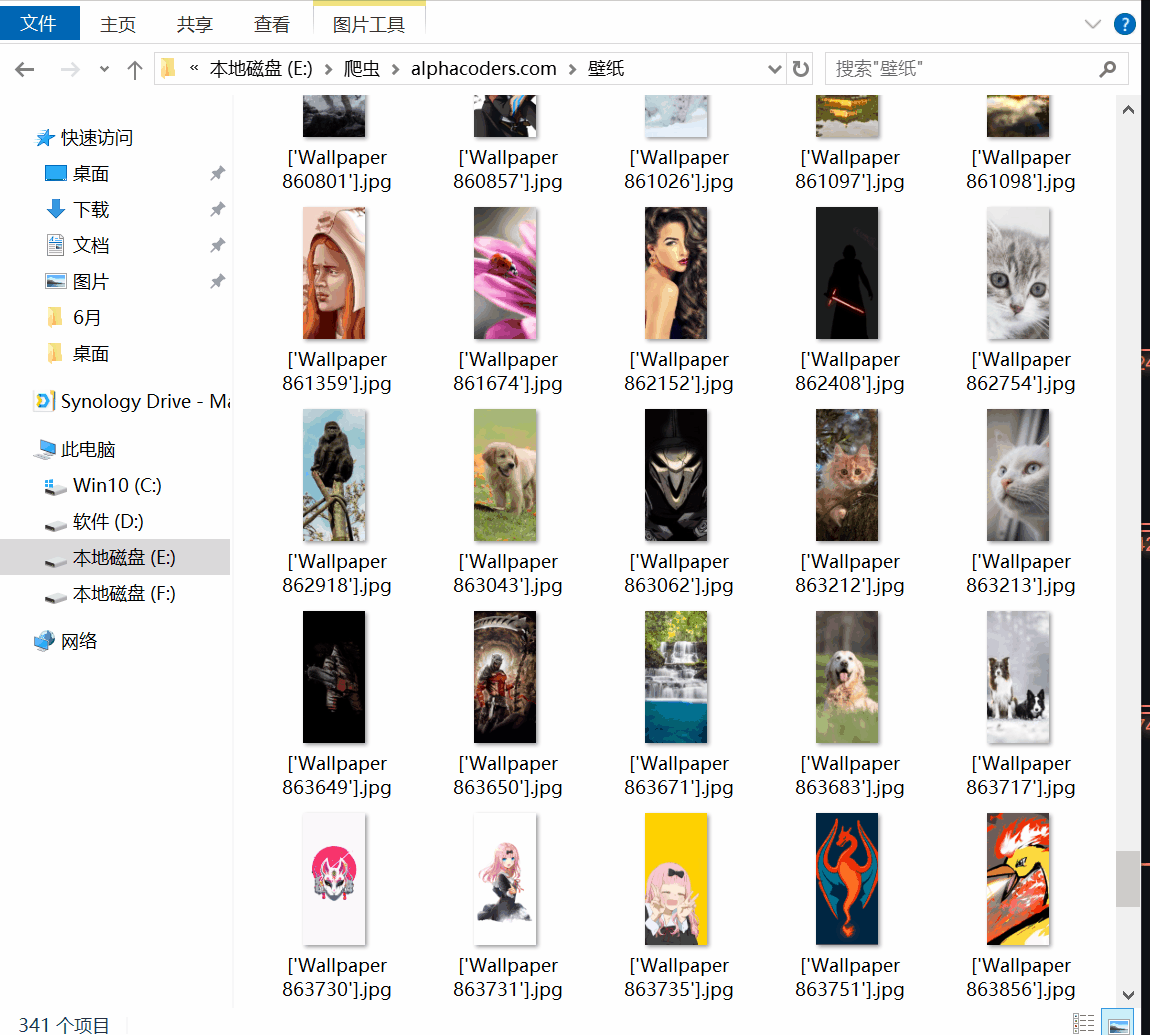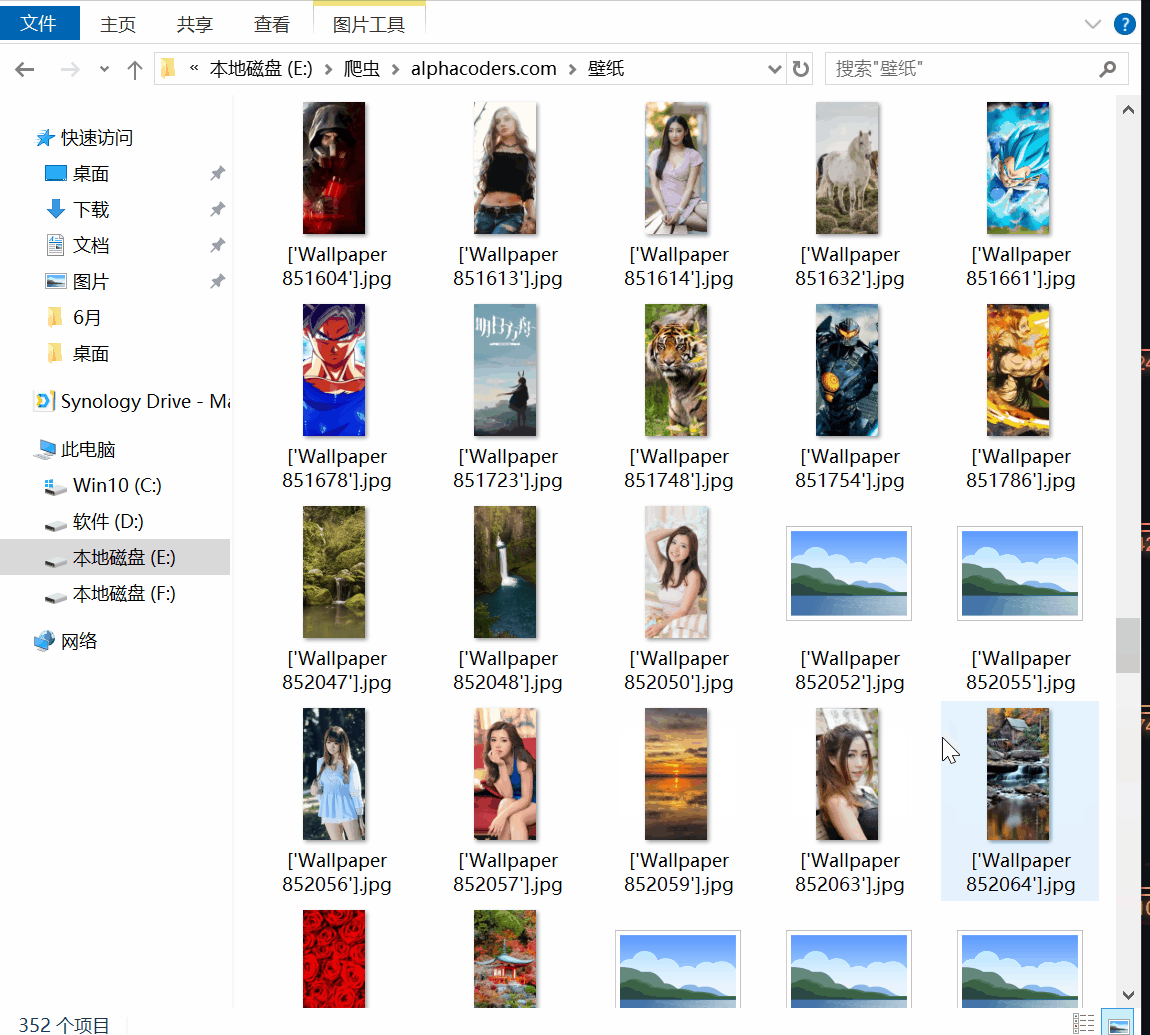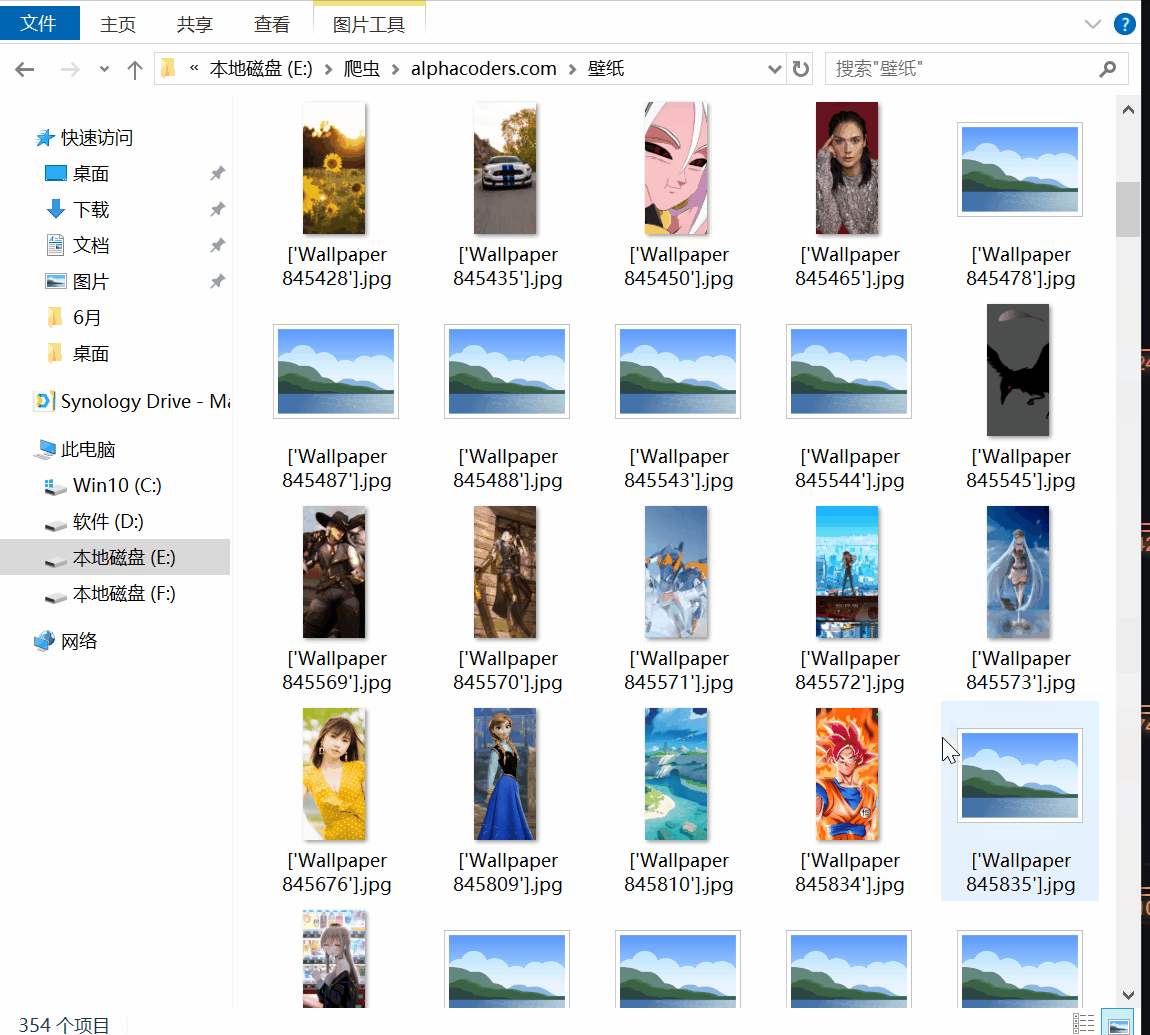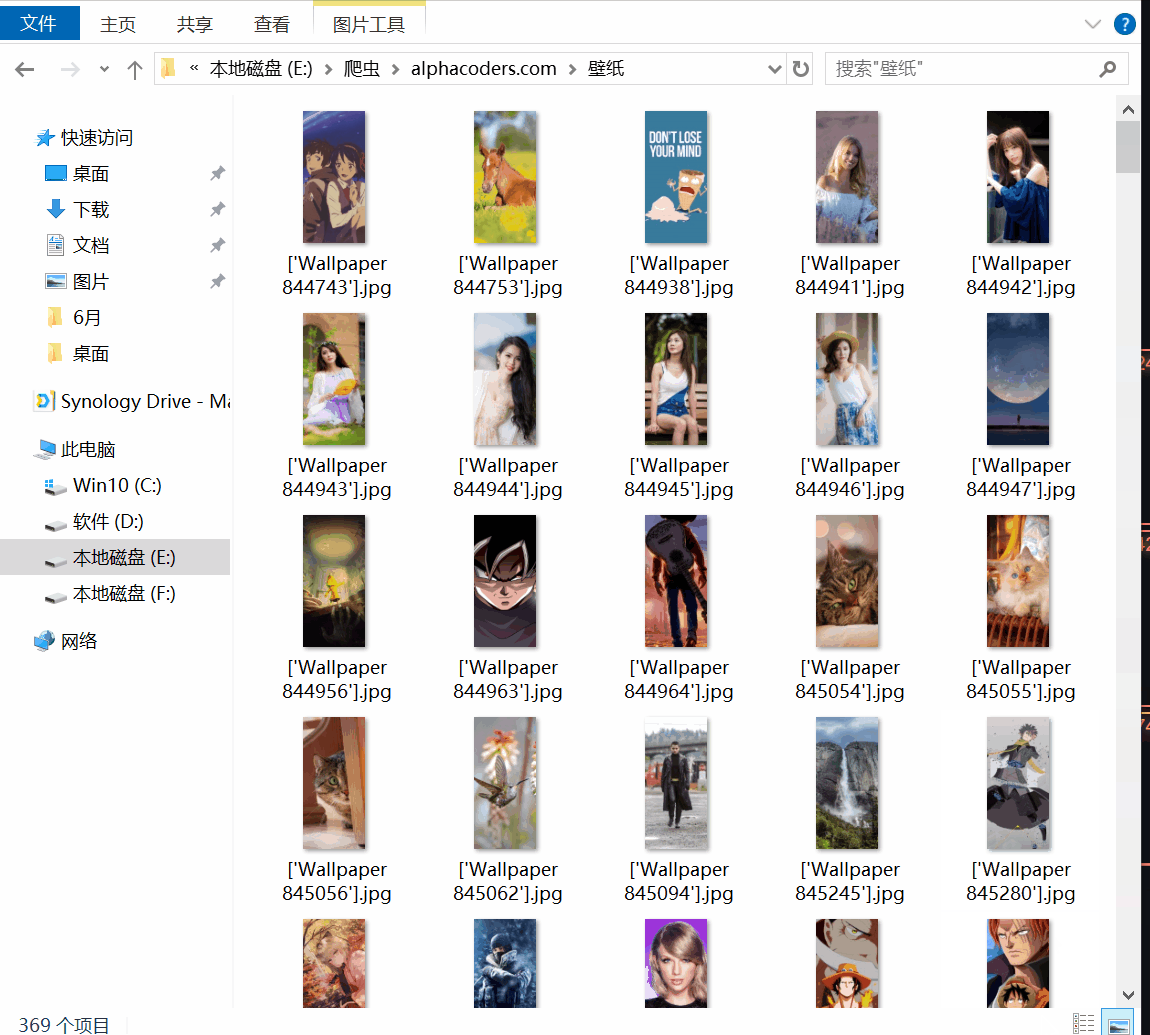
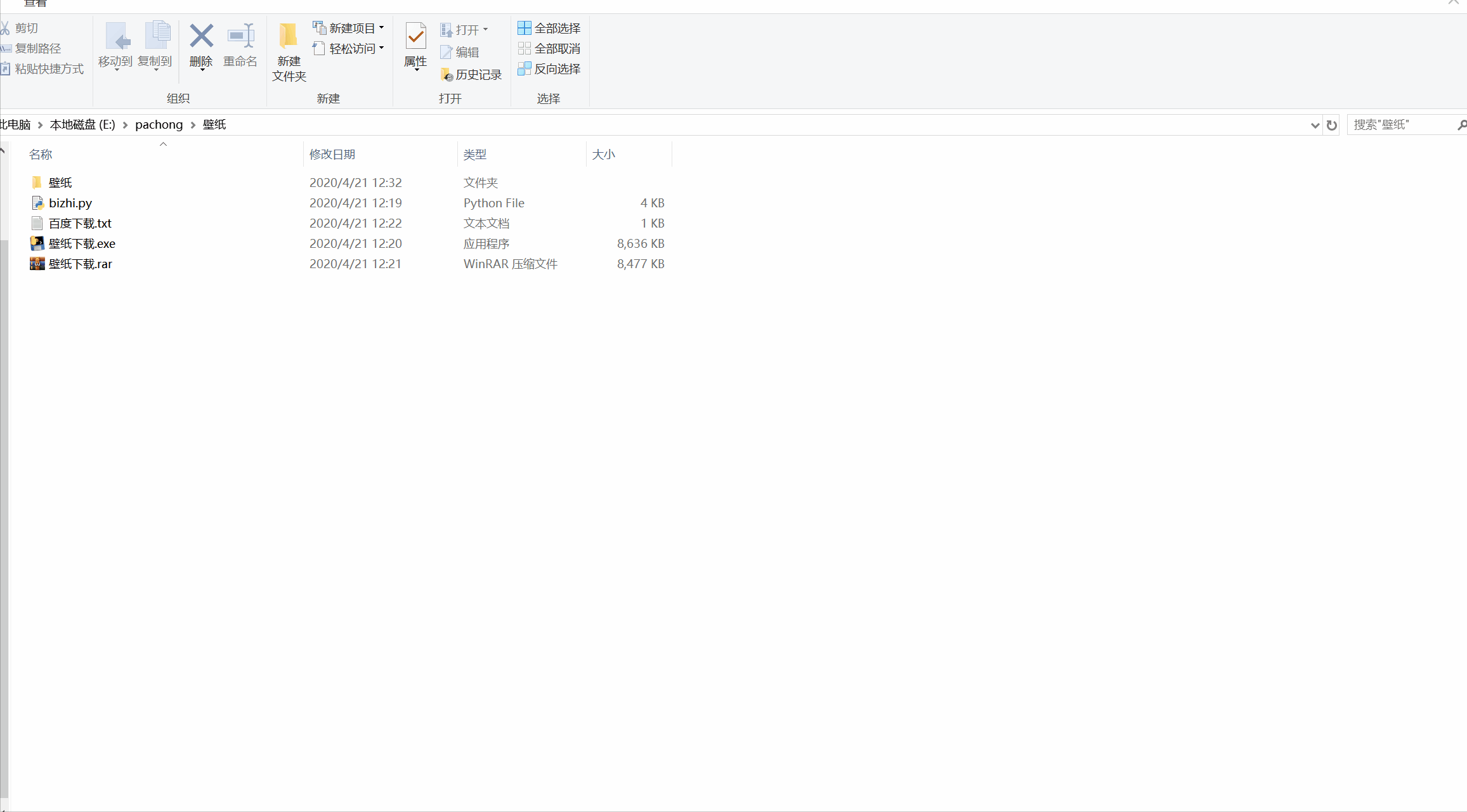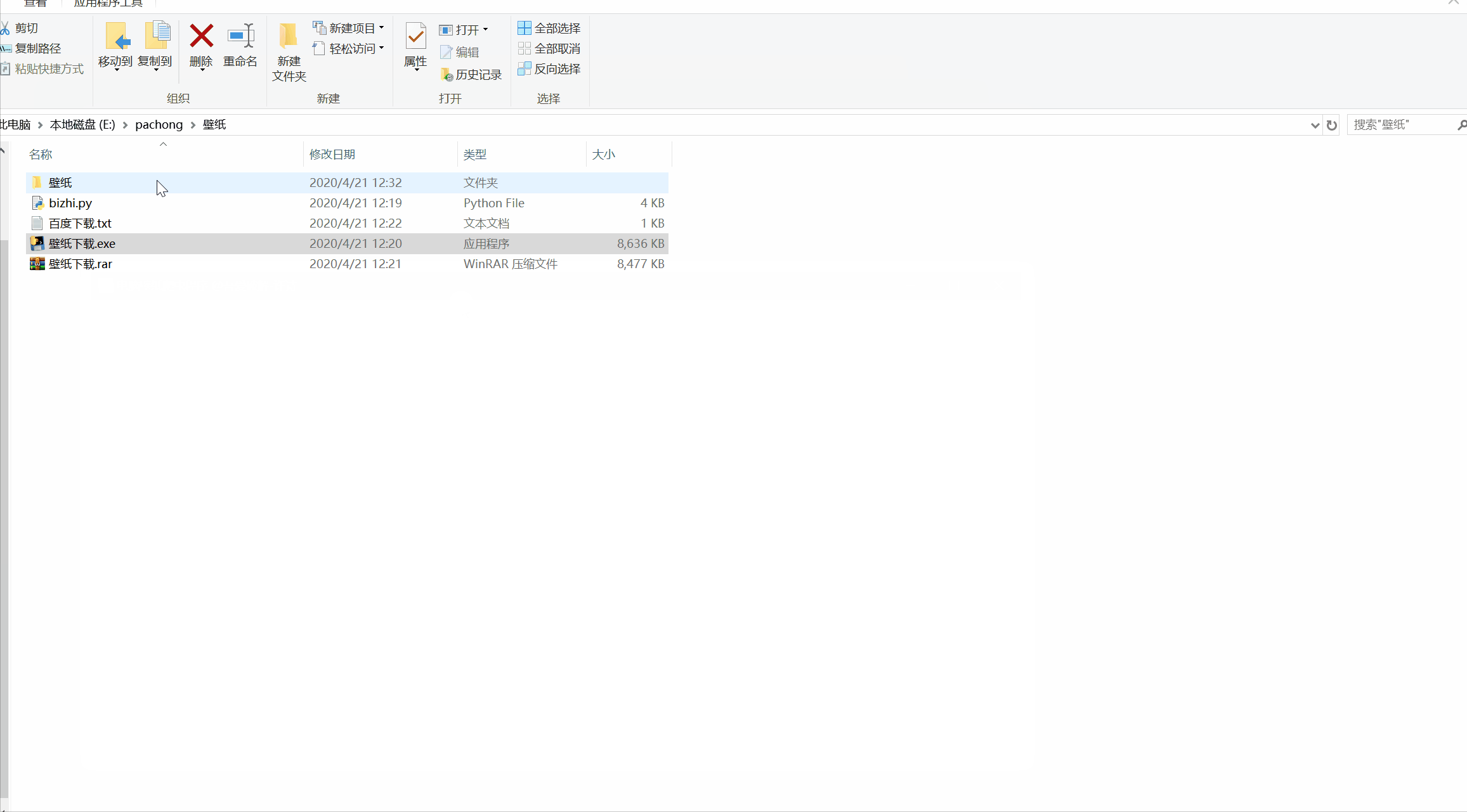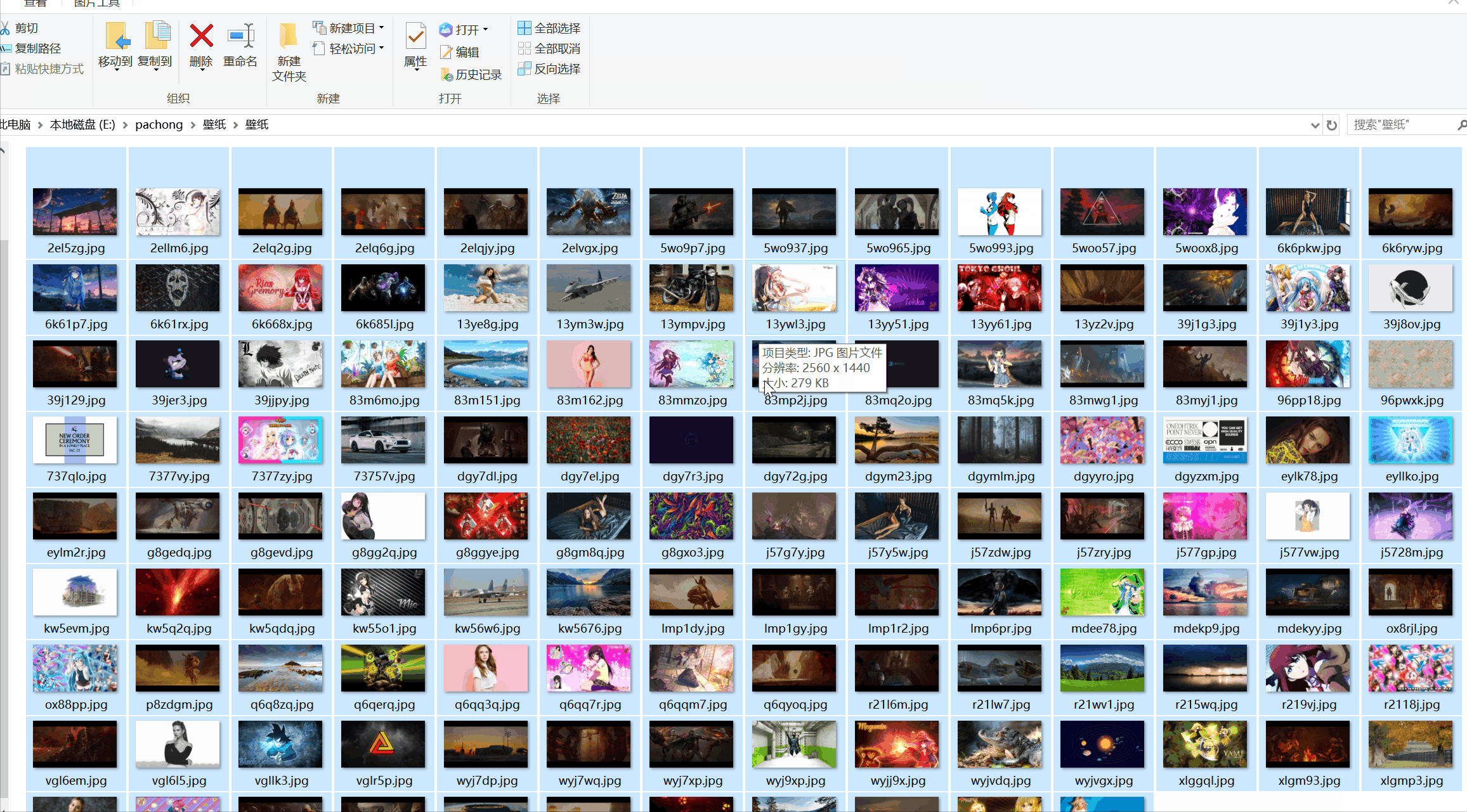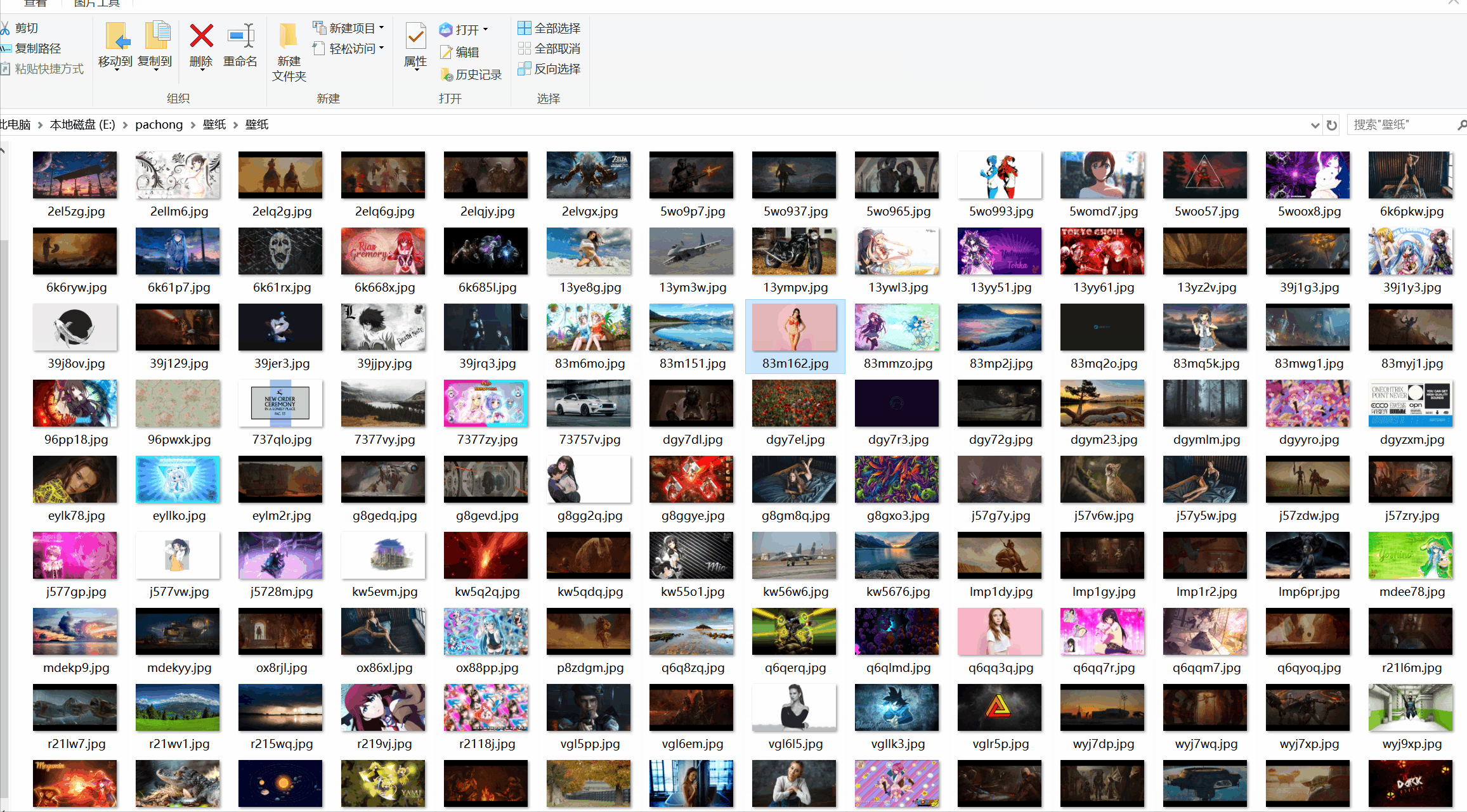
蓝奏云下载地址:https://wws.lanzous.com/iRmnqdpadri 有需求请在本贴留言,不再同步52pojie 2020-6-15-18:18 更新以下款手机壁纸选择 Sam...
20204.22 12:05更新需求分辨率 2020.4.22 09:213:新增留言中的需求分辨率:3440X14402020.4.21 12:16更新中本次更新内容:1.下载图片分辨率改为绝...
mark一下,明天继续 没写完,只写到了获取分页的最大page数量 2020年4月5日0:49 其实代码不多,由于不熟悉码了很久...import re import requests impo...
前几天看到一个阿朱的写真网站,心想留下地址,以后爬取练手,今天匆匆忙忙的很晚了赶来第一次练手,爬取是成功的,写的有点乱,暂时记录一下,以后有待优化 import requests import ...
照着书上的例子,所有代码照敲,发现爬不了,于是自己动手修改一下,连爬取的页面都该为hot了,可是发现好像是编码的问题,于是卡住了 经过1个小时的奋斗,被我修改了一下,但是由于这个直接抓取hot在...
刚学会正则,想着把我之前爬的教学课程代码优化一下,整了大半夜了发现无法匹配import os import re import requests download_path = './所有课本...
从下午大概3点半到现在0:24分,就围着这些代码敲和看了,有部分不明白,例如content是个什么玩意.不过照着敲了,到现在代码运行起来不报错,可是程序也一直不给反应,不知道为什么,记录一下,免...
这里我测试了一下爬取豆瓣电影top250的所有图片,为了便于测试,我没有每一页进入爬取大图,只是在每个list抓取小图,测试结果是成功的,接下来继续测试python的多线程给爬虫提速.#codi...
#coding:utf-8 import os from fake_useragent import UserAgent import requests from bs4 import Beau...