资源信息
万门大学 趣学Python爬虫课程,该套课程为视频课程,共92节课,通过该套课程可以学到Python基础、HTML、CSS、JavaScript、scrapy框架等等内容,另外,该套课程还附带了课件文档。
资源目录
1.1 什么是爬虫
1.2 爬虫的数据延伸
1.3 合理使用爬虫
1.4 爬虫的分类
1.5 爬虫的业务场景
1.6 关于反爬的说明
1.7 爬虫的基本原理
1.8 Show一个小案例
2.1 Python解释器的安装
2.2 IDE工具Pycharm的安装
2.3 PIP包管理工具的使用
2.4 修改PIP源为国内地址
3.1 爬虫必备基础知识介绍
3.10 多线程
3.11 实操演示:生成器和多线程
3.2 变量:基础类型
3.3 结构类型:列表
3.4 结构类型:字典
3.5 程序逻辑:if else
3.6 for循环
3.7 while循环
3.8 函数
3.9 迭代器和生成器
4.1 前端的构成和基本原理
4.2 前端三剑客Html、CSS、JavaScript(一)
4.3 前端三剑客Html、CSS、JavaScript(二)
4.4 前端三剑客Html、CSS、JavaScript(三)
4.5 浏览器(Chrome)的使用
4.6 实操演示:基于Django框架演示前端代码
5.1 网络请求:GET和POST
5.10 实操演示:百度图片爬取下载
5.2 构建一个爬虫的步骤
5.3 关于cookie和session
5.4 POST登录爬虫构建
5.5 实操演示:浏览器功能和参数的说明
5.6 实操演示:百度搜索内容爬取
5.7 实操演示:头条新闻爬取
5.8 实操演示:百度翻译和搜狗翻译爬取
5.9 实操演示:先登录再爬取
6.1 数据的筛选方式
6.2 数据提取之页面分析
6.3 数据正则提取
6.4 数据bs4lxml提取
6.5 数据xpath提取
7.1 实操演示:数据正则提取
7.2 实操演示:数据bs4lxml提取
7.3 实操演示:数据xpath提取
7.4 爬虫实战:互联网数据资讯(一)
7.5 爬虫实战:互联网数据资讯(二)
8.1 爬虫实战:中国证监会公告(一)
8.2 爬虫实战:中国证监会公告(二)
8.3 爬虫实战:中国证监会公告(三)
8.4 爬虫实战:中国证监会公告(四)
8.5 爬虫实战:电影网站爬取
9.1 数据的保存方式
9.2 数据库存取
9.3 Excel文档存取
9.4 TXT文档存取
9.5 附件的保存、下载
9.6 案例实践:隧道打法
9.7 案例实践解析
9.8 爬取网页分析
10.1 实操演示:TXT文档存取数据
10.2 实操演示:Excel文档存取数据
10.3 实操演示:数据库存取数据
10.4 爬虫实战:爬取房产网站(一)
10.5 爬虫实战:爬取房产网站(二)
10.6 爬虫实战:爬取房产网站(三)
10.7 爬虫实战:爬取房产网站(四)
11.1 框架学习前言
11.2 什么是框架
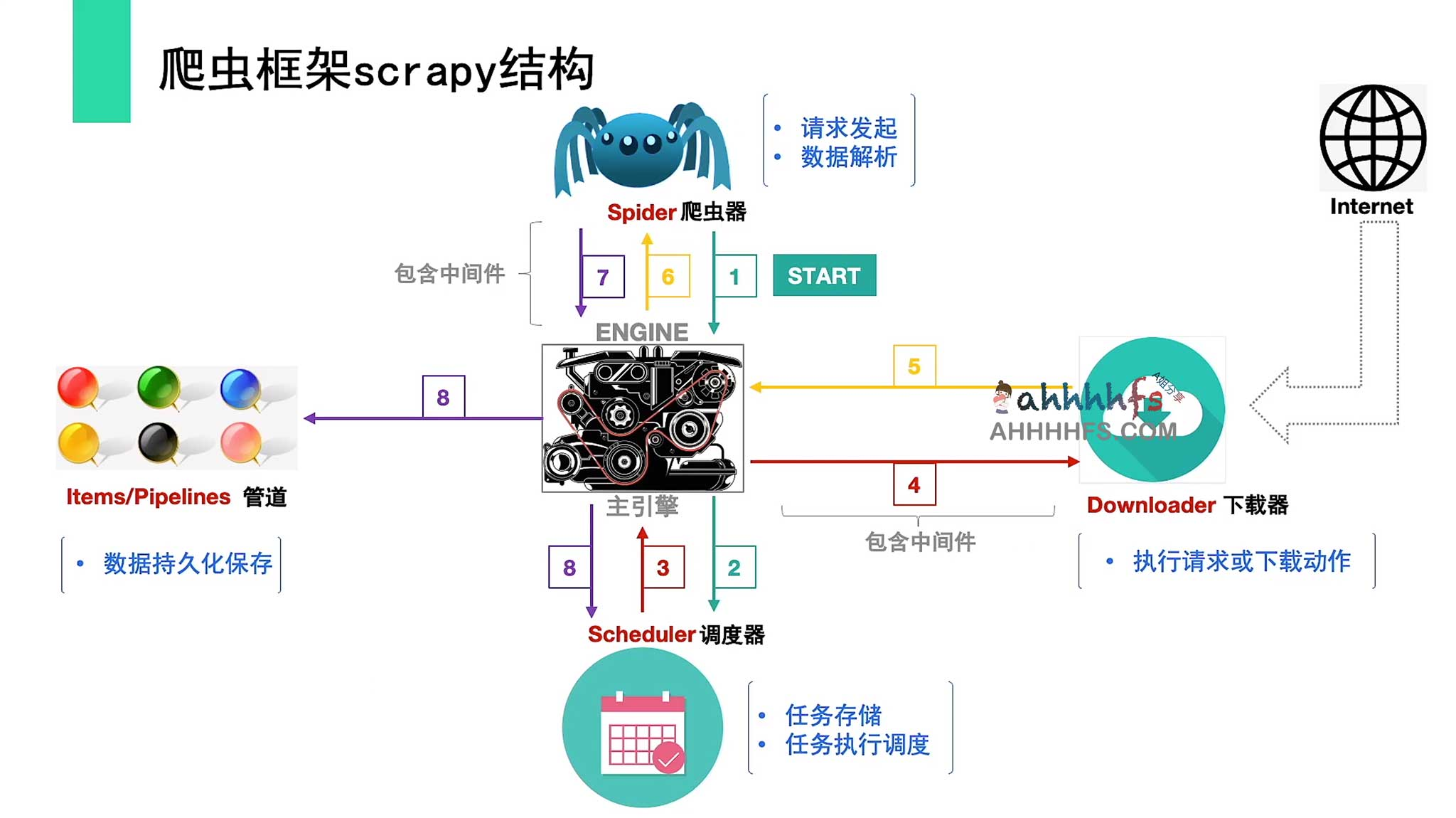
11.3 爬虫框架scrapy结构
11.4 scrapy框架组件
11.5 scrapy框架安装指南
11.6 如何使用scrapy框架
12.1 爬虫实战:scrapy框架(一)
12.2 爬虫实战:scrapy框架(二)
12.3 爬虫实战:scrapy框架(三)
13.1 scrapy框架的自定义请求
13.2 scrapy框架发起post请求
13.3 爬虫实战:自定义请求爬取多页
13.4 爬虫实战:自定义请求爬取二级页面
13.5 爬虫实战:爬取多页以及二级页面
13.6 爬虫实战:scrapy发起post请求
14.1 什么是分布式
14.2 scrapy实现分布式的关键
14.3 框架实现分布式的原理
14.4 实现分布式所需的环境
14.5 关于Redis的简单操作
14.6 关于Redis与scrapy框架配置
14.7 爬虫实战:分布式爬虫(一)
14.8 爬虫实战:分布式爬虫(二)
[ri-login-hide]
https://www.aliyundrive.com/s/u6p1cFPN6vZ
[/ri-login-hide]
